我正在实施 YOLO 网络并且有一些问题。在原始论文中,作者说:“对于预训练,我们使用图 3 中的前 20 个卷积层,然后是平均池化层和全连接层”。他们还报告说他们使用 ImageNet 1000 类数据集和 224x224 输入大小而不是 448x448
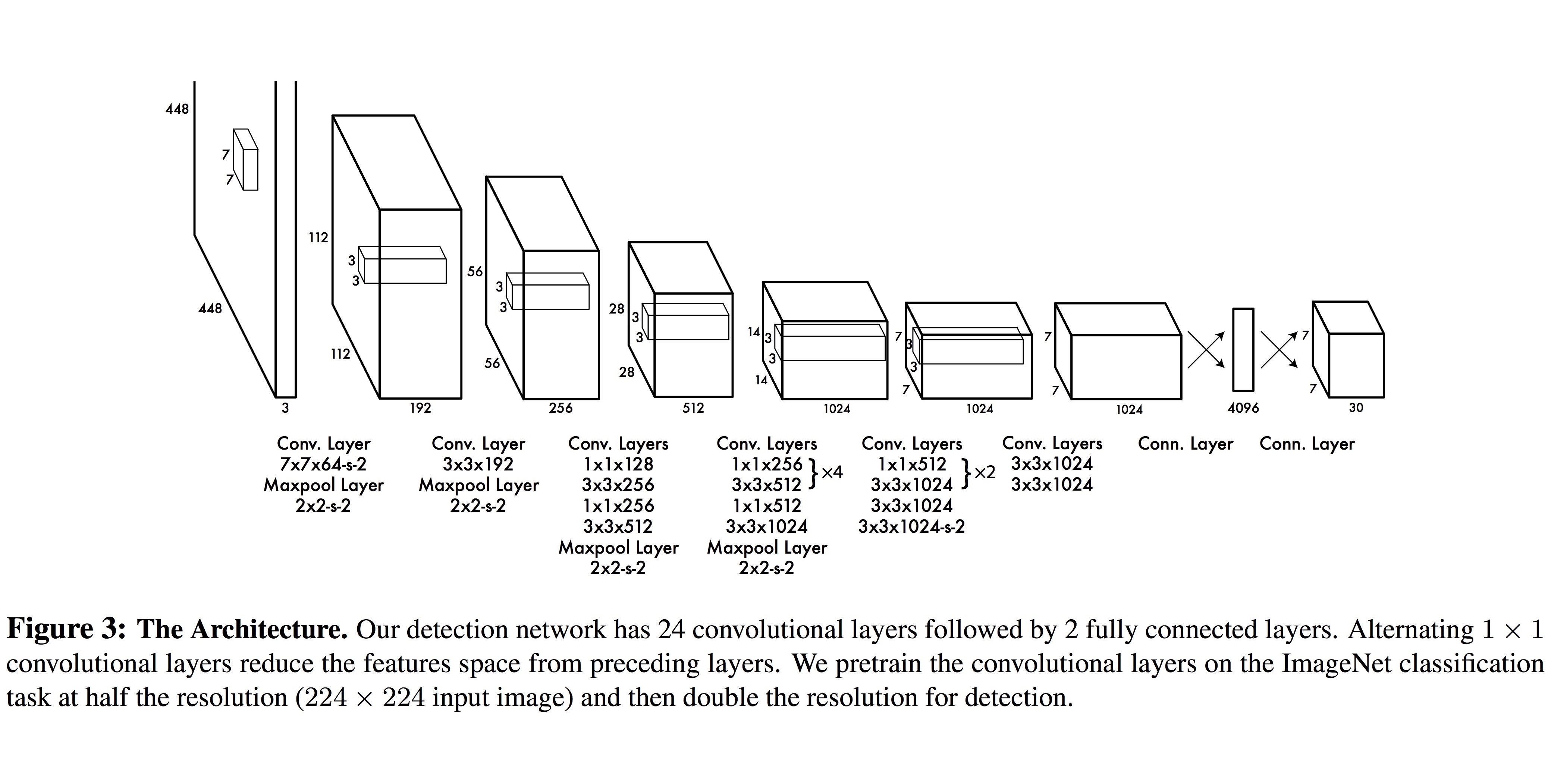
我的问题如下:
1)平均池化层内核的大小是多少?2x2?
2) 作者如何将输入大小减小到 224x224?他们省略了第一层吗?
我正在实施 YOLO 网络并且有一些问题。在原始论文中,作者说:“对于预训练,我们使用图 3 中的前 20 个卷积层,然后是平均池化层和全连接层”。他们还报告说他们使用 ImageNet 1000 类数据集和 224x224 输入大小而不是 448x448
我的问题如下:
1)平均池化层内核的大小是多少?2x2?
2) 作者如何将输入大小减小到 224x224?他们省略了第一层吗?
1)使用平均池化层(至少在这里)的目标是在它之后有一个向量。这样你就有了一个完全连接的层向量。
在 Yolo 中,全连接层之前的层似乎是 7x7x1024。下一层,全连接层,是 4096(或 1x1x4096)。这意味着您需要一个具有 7x7 内核和 4096 个过滤器 (7x7x4096) 的平均池化层。
也许看看Alexis Cook对 Global Average Pooling 的解释。
2)我不太明白你的第二个问题,所以如果我回答错误,请随时发表评论:
224x224 的维度是用于网络的预训练。首先,他们使用 imagenet 训练他们的网络进行图像分类,例如 VGG、Inception 或densenet 等网络。训练完成后,他们在开始时添加一个新层,输入大小为 448x448。他们用这个新的图像识别层再次训练了网络。